In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Apr 2025
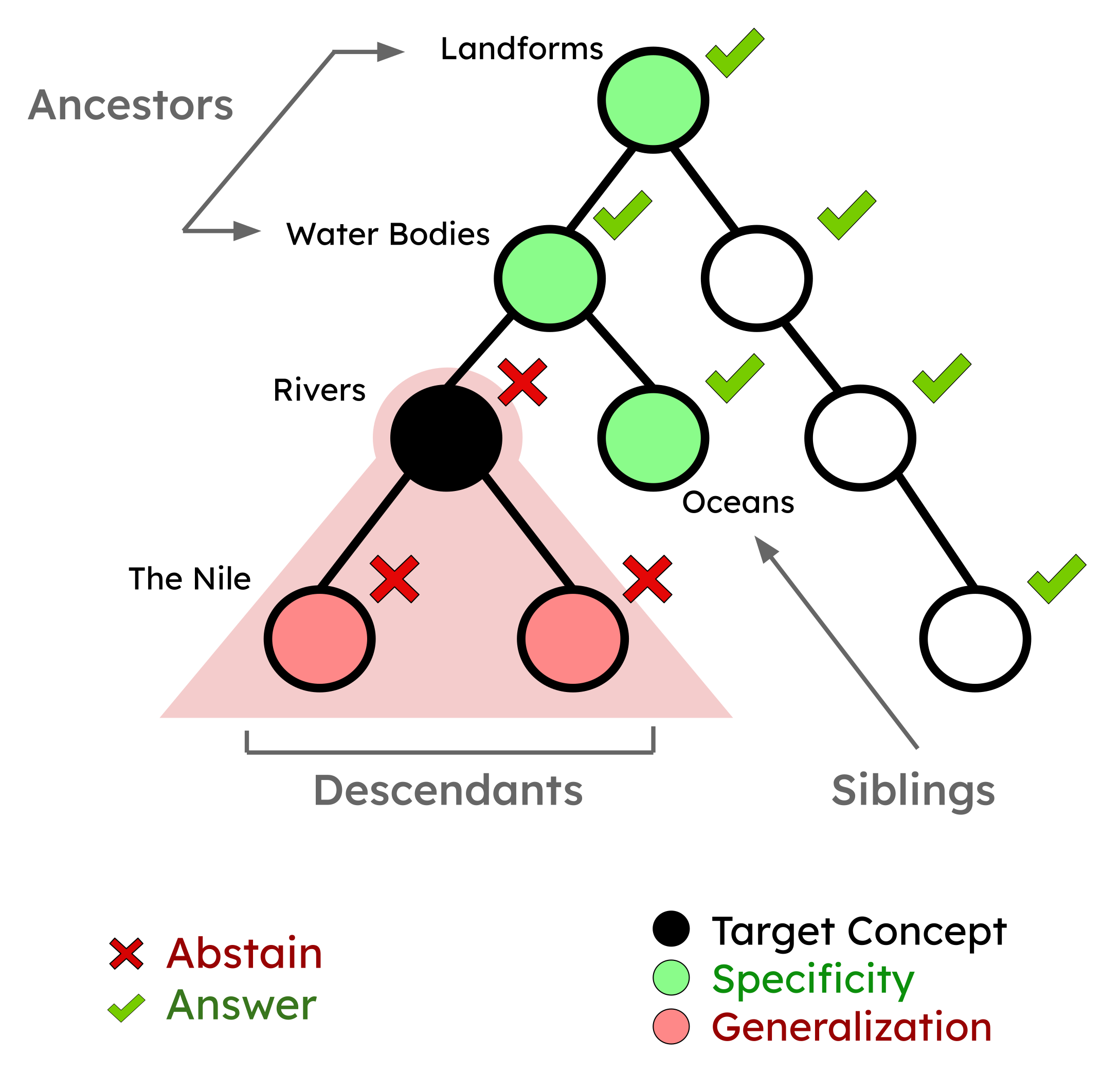
Using benign concepts from a knowledge graph (YAGO), we create a benchmark to evaluate abstention techniques for language models, where past abstention benchmarks prove insufficient.
To deploy language models safely, it is crucial that they abstain from responding to inappropriate requests. Several prior studies test the safety promises of models based on their effectiveness in blocking malicious requests. In this work, we focus on evaluating the underlying techniques that cause models to abstain. We create ‘SELECT‘, a benchmark derived from a set of benign concepts (e.g., “rivers”) from a knowledge graph. Focusing on benign concepts isolates the effect of safety training, and grounding these concepts in a knowledge graph allows us to study the *generalization* and *specificity* of abstention techniques. Using ‘SELECT‘, we benchmark different abstention techniques over six open-weight and closed-source models. We find that the examined techniques indeed cause models to abstain with over 80% abstention rates. However, these techniques are not as effective for descendants of the target concepts, where abstention rates drop by 19%. We also characterize the generalization-specificity trade-offs for different techniques. Overall, no single technique is invariably better than others, and our findings inform practitioners of the various trade-offs involved.
@inproceedings{vasisht-etal-2025-knowledge,title={Knowledge Graph Guided Evaluation of Abstention Techniques},author={Vasisht, Kinshuk and Kaur, Navreet and Pruthi, Danish},editor={Chiruzzo, Luis and Ritter, Alan and Wang, Lu},booktitle={Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)},month=apr,year={2025},address={Albuquerque, New Mexico},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2025.naacl-long.353/},doi={10.18653/v1/2025.naacl-long.353},pages={6921--6939},isbn={979-8-89176-189-6},}
In Findings of the Association for Computational Linguistics: NAACL 2025, Apr 2025
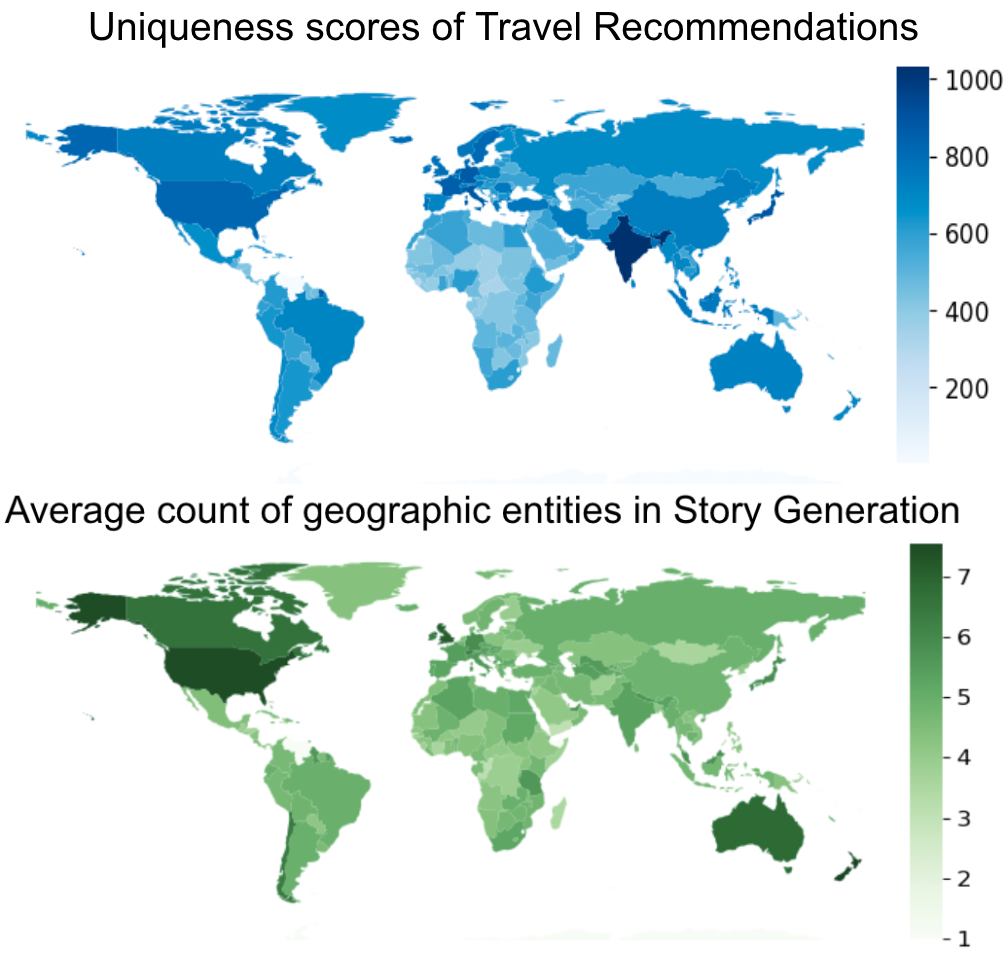
Using real-world tasks of travel recommendation and story generation, we uncover geographical disparitites in language models that a lack of knowledge alone cannot explain.
While a large body of work inspects language models for biases concerning gender, race, occupation and religion, biases of geographical nature are relatively less explored. Some recent studies benchmark the degree to which large language models encode geospatial knowledge. However, the impact of the encoded geographical knowledge (or lack thereof) on real-world applications has not been documented. In this work, we examine large language models for two common scenarios that require geographical knowledge: (a) travel recommendations and (b) geo-anchored story generation. Specifically, we study five popular language models, and across about 100K travel requests, and 200K story generations, we observe that travel recommendations corresponding to poorer countries are less unique with fewer location references, and stories from these regions more often convey emotions of hardship and sadness compared to those from wealthier nations.
@inproceedings{bhagat-etal-2025-richer,title={Richer Output for Richer Countries: Uncovering Geographical Disparities in Generated Stories and Travel Recommendations},author={Bhagat, Kirti and Vasisht, Kinshuk and Pruthi, Danish},editor={Chiruzzo, Luis and Ritter, Alan and Wang, Lu},booktitle={Findings of the Association for Computational Linguistics: NAACL 2025},month=apr,year={2025},address={Albuquerque, New Mexico},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2025.findings-naacl.262/},doi={10.18653/v1/2025.findings-naacl.262},pages={4645--4653},isbn={979-8-89176-195-7},}
In Proceedings of the 20th International Conference on Natural Language Processing (ICON), Dec 2023
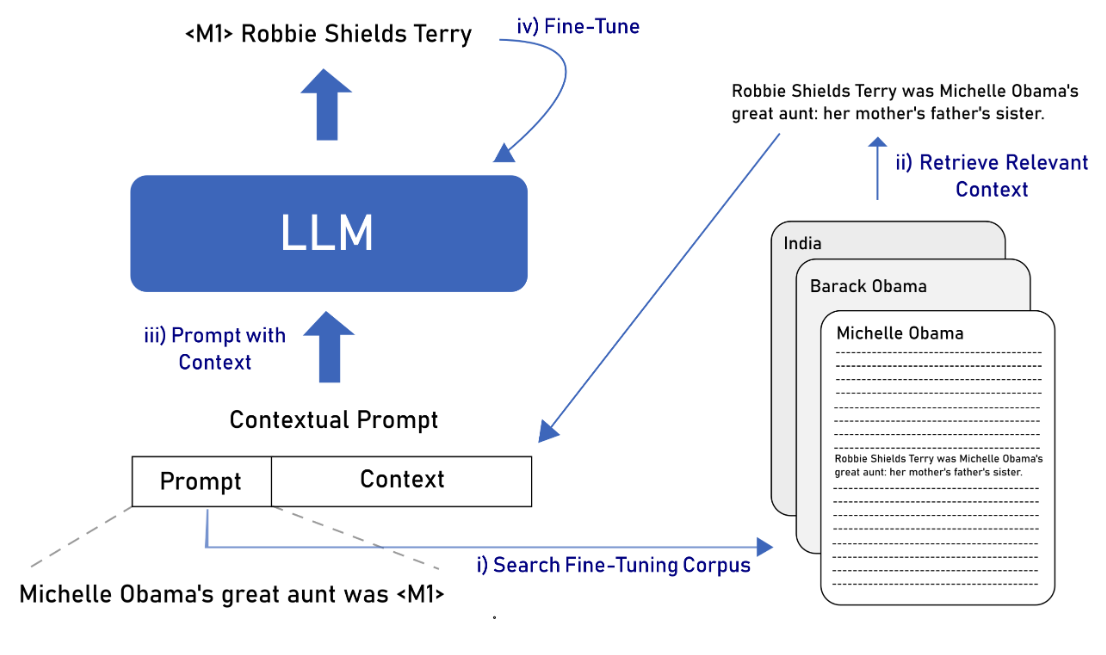
We explore the use of contextualized prompts as a promising approach for knowledge infusion, in contrast to training over triples from knowledge graphs.
Knowledge infusion is a promising method for enhancing Large Language Models for domainspecific NLP tasks rather than pre-training models over large data from scratch. These augmented LLMs typically depend on additional pre-training or knowledge prompts from an existing knowledge graph, which is impractical in many applications. In contrast, knowledge infusion directly from relevant documents is more generalisable and alleviates the need for structured knowledge graphs while also being useful for entities that are usually not found in any knowledge graph. With this motivation, we propose a simple yet generalisable approach for knowledge infusion by generating prompts from the context in the input text. Our experiments show the effectiveness of our approach which we evaluate by probing the fine-tuned LLMs.
@inproceedings{vasisht-etal-2023-infusing,title={Infusing Knowledge into Large Language Models with Contextual Prompts},author={Vasisht, Kinshuk and Ganesan, Balaji and Kumar, Vikas and Bhatnagar, Vasudha},editor={D. Pawar, Jyoti and Lalitha Devi, Sobha},booktitle={Proceedings of the 20th International Conference on Natural Language Processing (ICON)},month=dec,year={2023},address={Goa University, Goa, India},publisher={NLP Association of India (NLPAI)},url={https://aclanthology.org/2023.icon-1.65/},pages={657--662},}